
Naxi Dongba
CL.A.U.D.I.A.: Computational and Updatable Dongbas Iconographic Archive
CLAUDIA
- Home
- Introduction
- + Pictograph iconographic plates
- + English dictionary by keyword search (sperimental!)
- Introduction and howto page
- Keyword search engine
- Pictographs dictionary by Naxi initial syllables
- + Naxi Dongba Home
- Home page
 |
| 
- Home page

CLAUDIA ICONOGRAPHIC PRIMES PLATES of Dongba pictographs
Pictograph plates resources conception is derived directly from Egyptian Dictionary structure written by Sir Alan Gardiner in its landmark work Egyptian Grammar, where he settled some indexed categories under which he collected Egyptian hieroglyphics.

Gardiner's index lists of hieroglyphics
Each plates had a keyletter and the Hieroglyphs stored within was tagged by crescent identification number, and the same index system was structured by the following Egyptian dictionary.

Gardiner's index hieroglyphics dictionary. Such related work of index ‹--› dictionary is foundamental model for CL.A.U.D.I.A.'s structure.
Iconographic and semantic indexed plates of Gardiner's Egyptian Dictionary constitute a very useful tool for faster identification of hieroglyphics, and its adoption - here fitted to the Dongba pictographic system - will systematize other researcher's efforts in documenting the Dongba written language.
I classified pictographs by their own characteristics, of which to me the most important seem to be: 1. iconography and 2. shape (for unidentified pictograph). Both will be indexed.
- Iconographic classification of pictographs should coincide with the identification of the prominent pictographical aspect of the significant operation, in other words what the analysed pictograph is depicting (in ex. the head of a bird, part of human body, a craft, etc...) must be identified
- By Grouping of unidentified pictograph by shape an operation is meant, founded on a preliminary aesthetic/geometric normalization of dubious and unidentified pictograph to fit them into a geometric standard whole, as round, vertical, horizontal, crux, elliptic, dots, etc... Such classification should be the most useful and the only efficient for attested but unidentified or uncertain pictographs.
Each entry in Pictographs plates will show, from top to bottom
- category, subcategory ID
- Pictograph reproduction (a .png image)
- latinization
- [IPA phonetic standard] transcription
- references and quotations of the main Dongba/Geba dictionaries work with local ortography
In CALUDIA system each significant, will be the N th element the M th category.
For instance, pictograph ![]() will be the N th pictograph (here N=10) of the M th category
(here M=E alias Animals) and yth
category (here y=a alias Complete)
will be the N th pictograph (here N=10) of the M th category
(here M=E alias Animals) and yth
category (here y=a alias Complete)
Animals, Complete

Thus ![]() is the 10th entry of the E.Animals pictograph category,
a.Complete pictograph subcategory. Its latinization,
following Pinson and McKhann orthography is /la/ with 1st
ascendant tonal accent tagged by number 2 final. It's IPA pronounce
transcription is [lɑ33]. This pictograph is recorded in Dragan
Janekovic as the 557th pictograph, translitered with /la33/
ortography; in Fang Guoyu He Zhiwu at pg. 409, the bth pictograph
(from the top of each page a for the 1st, b for the 2nd,
and so go on to the down), traslittered as /lɑ33/; in Hè Pǐn
Zhèng it's on pg. 43, the fth with /lɑ33/ ortography
and finally in Li Lincan it's the 761st pictograph, translitered
/la33/, as the the 556th.
is the 10th entry of the E.Animals pictograph category,
a.Complete pictograph subcategory. Its latinization,
following Pinson and McKhann orthography is /la/ with 1st
ascendant tonal accent tagged by number 2 final. It's IPA pronounce
transcription is [lɑ33]. This pictograph is recorded in Dragan
Janekovic as the 557th pictograph, translitered with /la33/
ortography; in Fang Guoyu He Zhiwu at pg. 409, the bth pictograph
(from the top of each page a for the 1st, b for the 2nd,
and so go on to the down), traslittered as /lɑ33/; in Hè Pǐn
Zhèng it's on pg. 43, the fth with /lɑ33/ ortography
and finally in Li Lincan it's the 761st pictograph, translitered
/la33/, as the the 556th.
Each pictograph here represented in small size with pinyin [IPA], attestation and draft translation is an hyper-lynk. By clicking on it, if implemented, You open in _blank page a complete pictograph schedule with translation, explanation, description and attestation of the specific pictograph and its variants: this is CL.A.U.D.I.A. 东巴象形文字词典 Dongba Pictographic Dictionary as I thought and implemented it as wide-web fruible resources.
E. plate, alias ANIMALS BASE ICONOGRAPHY pictographs plate
E. plate is about animal iconography pictographs, regardless of the meaning and/or the pronouncing, and pictographs directly gathered into E. plate are BASE - ICONOGRAPHY pictographs.
By base iconography here is meant as a fundamental graphic unit which could be iconographically brought to representation of an animal or a part of animal, excluding reptiles, birds and fishes, which are going to be study and gathering in further work, implementing separated and dedicated plates.
For more details see below Markup and tagging pictographs by STRUCTURAL criteria.
E.a. Complete, E.b. Parts of animals sub-plates
As introduced upper, animal's base pictographs are sorted and divided among 2 main sub-categories, identified and evicted from analysis of animal's iconography pictograph corpus:
- a. Complete
- b. Parts of animals
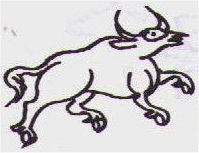
a. Complete sub-category collects the whole base pictographs having
it basic graphical unit directly matching with a complete-portrait figure
of animal, as  ,
,
 ,
,  ,
etc....: each entry in Ea. Plate, as ,
will be presented as following
,
etc....: each entry in Ea. Plate, as ,
will be presented as following
As introduced upper, Naxi pinyin - alias latinization - is related and accorded with McKhann and Pinson ortography, also to Alexis Michaud work, expecially for Rock ortography conversion and IPA reconstruction (Michailovsky, Boyd; Michaud, Alexis, 2006); tones ortography is adopted from Janekovic (2002) because at me resulted the quickest and usefullest.
Markup and tagging pictographs by ICONOGRAPHY criteria
Each pictograph in CL.A.U.D.I.A. System (hence CLAUDIAs) has iconographic
tags, they are marked-up to each pictograph just following ICONOGRAPHIC
- AESTHETIC criteria, thus pictographs were distinguished as introduced
before at first among Complete and Parts of animal: i.e.,
E.a.14 get <complete> tag, whilst  E.b.53
gets <pofanimal>, where pofanimal means parts_of_animal.
E.b.53
gets <pofanimal>, where pofanimal means parts_of_animal.
E.b.53 then got
<headanimal>, after that
and both take
<horned> and <bovine>.
Such tags are stored in "ICONOGRAPHY" field of MySql table "animals" of Dongba pictographs database; ICONOGRAPHY filed is also used for ordering by alphabetic ascending as default option whence disposing plates list of pictographs browsing CL.A.U.D.I.A..
Some exemples of iconography markup:
 Ea10: <animal>, <complete>, <feline>, <tiger>
Ea10: <animal>, <complete>, <feline>, <tiger> Eb31: <animal>, <pofanimal>, <feline>, <headanimal>,
<tiger>
Eb31: <animal>, <pofanimal>, <feline>, <headanimal>,
<tiger> Z : <strokes>, <3>, <diagonal>, <leftright>
*
Z : <strokes>, <3>, <diagonal>, <leftright>
*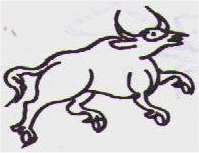 Ea14: <animal>, <complete>, <horned>, <cow>
Ea14: <animal>, <complete>, <horned>, <cow> Eb53: <animal>, <pofanimal>, <horned>, <head>,
<cow>
Eb53: <animal>, <pofanimal>, <horned>, <head>,
<cow>
Z plate: undefined pictographs
* According to close iconographic mark-up criteria, pictographs like
Eb72 got other tags, specifically: <strokes>, <diagonal>,
<stripes>, 'cause although Eb72
meaning is the stripes of the tiger, is a-posteriori information which
we suppose common users browsing CLAUDIA shouldn't know, thus such information
is non-usefull to CLAUDIA iconographic mark-up of pictographs, and Eb72
then results ICONOGRAPHIC-ALLY INCOMPATIBLE with animal group, thus
it is sorted into Z plate of strokes and undefined pictographs.
Obviously Z undefined and strokes category has other kind of tags, yet iconographic-ally based to marking-up to pictographs for their iconography, but following simple geometric features, as undefined pictograph is made:
- by strokes, dots, both,
- how many units is made of,
- it is vertical, horizontal or diagonal,
- its orientation (from top to bottom)
in other words iconographic-ally undefinable pictographs are normalized and inscribed into simple geometric shapes, as exemplified below:
Z:
<strokes>, <3>, <diagonal>, <leftright>,
<stripes> Z:
<strokes>, <1>, <diagonal>, <leftright>,
<curve>, <twirl>
Z:
<strokes>, <1>, <diagonal>, <leftright>,
<curve>, <twirl>  Z:
<strokes>, <4>, <diagonal>, <rightleft>, <curve>
Z:
<strokes>, <4>, <diagonal>, <rightleft>, <curve>Markup and tagging pictographs by STRUCTURAL criteria
CLAUDIAs also foresee a structural and semantic tagging of pictographs, both have to be projected and implemented according to actually L.C. requirements and W3C recommendations.
For structural markup, at today is just implemented a <base> or <not_base> mark-up, stored in META field of animal MySql table of CLAUDIAs: such pair of values specifies for each pictograph its STRUCTURE AS A BASIC OR NOT GRAPHIC UNIT, with or without addiction of more units (other base|not base pictographs, or Geba phonetics) building up a composed and/or fusion pictographic unit (not basic anymore).
In other words <base> mark-up identifies ATOMIC UNIT or TOKEN into iconographic-animals pictographs corpus, whilst and <not_base> mark-up is tagged to NON-ATOMIC or COMPOSED UNITS into the same corpus.
What's peculiar in such kind of TOKENIZATION operation is ICONOGRAPHY criteria of tokenization itself: ICONOGRAPHY MARKING-UP seems not to be melted or mare with linguistic data, although somehow and somewhere LINGUISTIC and ICONOGRAPHY features may are in close relationship, iconography marking-up seemed not to be the right setting of linguistic data consideration, which could be causes of background noise, and have to be implemented apart in CL.A.U.D.I.A.s. dedicated field.
Thus and
pictographs, both are <base> and both are attested as a basic
iconographic and structural unit for a set of <not_base> pictographs
as listed below:
- For E.a.14
we have
 ,
,  ,
,
 ,
,  and
and  .
. - For E.b.53
we have
 ,
,  ,
,
 ,
,  ,
,
 ,
,  ,
,
 ,
,  ,
,
 ,
,  ,
,
 and
and  .
.
Markup and tagging pictograph by SEMANTIC criteria

A very draft semantic pictographs specifications is stored into TRANSLATION and EXPLAIN visible fields and META hidden field of animals MySql table of CLAUDIA's pictograph database.
TRANSLATION field records meaning(s) of each pictograph (<base> or <not_base>) in English language; in case of polyphonic and poly-semantic pictographs (both often) various meanings are gathered below respectively reading, for instance:
Meta hidden field records other semantic specification but not directly implicated with "the meaning" or "translation" of pictographs, then in META field is possible to insert also related key-words, as hidden voices to users browsing pictographs plates, but functional for Information Retrival operation in CLAUDIAs.
I.e.:
is a poly-semantic and poly-phonic pictograph, with 3 readings attested:
mo3 [mo31], le1 [l?55] and ee2 [?33]. All could mean a cow, or a general
cattle bovine, but just mo3 [mo31] reading could mean sacrificial cattle.
TRANSLATION field contains just the voice cow, whilst META filed contains some keywords as poly-semantic, poly-phonic, religion and ceremony, etc...
Another sample of poly-phonic and poly-semantic pictograph is  :
i2 [i33], i1 [i55] and i2 i2 [i33 i33].
:
i2 [i33], i1 [i55] and i2 i2 [i33 i33].
Reading i2 [i33] it means:
- a serow, Capricornus sumatrensis milne edwardii,
- to be capable of loving,
- to be as existing.
By i1 [i55] reading it means:
- to praise, to loud,
- to leak, as a basket or jug.
By i2 i2 [i33 i33] means:
- to entertain.
NSM Semantic Mark-up for Dongba Pictographs
The theory known as Natural Semantic Metalanguage has been developed by A. Wierzbicka and, later, by C. Goddard and other scholars.
The basic idea is that we should try to describe complex meanings
in terms of simpler ones. For example, to state the meaning of a semantically
complex word we should try to give a paraphrase composed of words which
are simpler and easier to understand than the original. This method
of semantic description is called reductive paraphrase. It prevents
us from getting tangled up in circular and obscure definitions, problems
which bedevil conventional dictionaries and other approaches to linguistic
semantics. No technical terms, neologisms, logical symbols, or abbreviations
are allowed in a reductive paraphrase only plain words from ordinary
natural language. (NSM Semantics in Brief: http://www.une.edu.au/bcss/linguistics/nsm/semantics-in-brief.php
? 2009, June 28
By reductive paraphrase is thus possible to proceed as method for meaning analysis, which conduces to every languages semantic core, a language-like structure, with a lexicon of indefinable expressions ("semantic primes") and a grammar [...] governing how the lexical elements can be combined : in other words a mini-language as expressive powerful as full natural language.
Semantic complex concepts thus could be explained by reductive paraphrase method, for instance a pair of samples from Wierzbicka 1996: 251-253; Goddard 1988):
- Semantic emotion terminology: feeling invidious
- X felt invidious =
- X felt something bad
- because X thought like this about someone else:
- something good happened to this person
- it didnt happened to me
- this is bad
- I want things like this happen to me
- X felt invidious =
- Causative verb break, as Person-X broke Y (ex.: Pete
broke the window)
- X broke Y =
- X did something to Y
- because of this, something happened to Y at this time
- because of this, after this Y wasnt one thing any more
- X broke Y =
Anna Wierzbicka aiming always to reduce the terms of the explications to the smallest and most versatile set by experimentation: she thus identified a core of 60 semantic primes (Goddard & Wierzbicka, Meaning and Universal Grammar, Eds 2002)
Semantic primes like I, YOU, SOMEONE, SOMETHING, THIS, HAPPEN, MOVE, etc.., identifying simples and intuitively intelligible meanings, are essential for numerous other words meaning explicating and non-circular grammatical constructions.
According to Wierzbicka, English core at today consists in:
- Substantives: I, YOU, SOMEONE, PEOPLE, SOMETHING/THING, BODY
- Relational substantives: KIND, PART
- Determiners: THIS, THE SAME, OTHER/ELSE
- Quantifiers: ONE, TWO, SOME, ALL, MUCH/MANY
- Evaluators: GOOD, BAD
- Descriptors: BIG, SMALL
- Mental predicates: THINK, KNOW, WANT, FEEL, SEE, HEAR
- Speech: SAY, WORDS, TRUE
- Actions, events, movement, contact: DO, HAPPEN, MOVE, TOUCH
- Location, existence, possession, specification: BE (SOMEWHERE),THERE IS, HAVE, BE (SOMEONE/SOMETHING)
- Life and death: LIVE, DIE
- Time: WHEN/TIME, NOW, BEFORE, AFTER, A LONG TIME, A SHORT TIME, FOR SOME TIME, MOMENT
- Space: WHERE/PLACE, HERE, ABOVE, BELOW, FAR, NEAR, SIDE, INSIDE
- "Logical" concepts: NOT, MAYBE, CAN, BECAUSE, IF
- Intensifier, augmentor: VERY, MORE
- Similarity: LIKE
Such primes are could well been implemented as Xml well-formed tree, constructing a NSM ontology skeleton, as exemplified below:

Implementation of NSM Semantic Mark-up for Dongba pictographs thus consists in:
-
annotations of English translation of CL.A.U.D.I.A. stored Dongba pictographs by NSM English semantic core marking-up
For instance: pictograph
Ea1 will be semantically marked-up as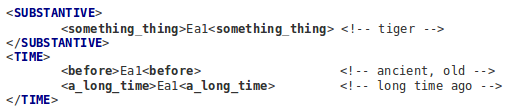
Such sample represents a very basic approach to Dongba pictographs NSM mark-up I am working over.
NSM studies have been carried out in a wide range of a languages, including English, Russian, French, Spanish, Polish, Italian, Ewe, Malay, Japanese, East Cree, Chinese, Mbula, Yankunytjatjara, Arrernte, and Maori, among others.
Considering Naxi language and Dongba pictograph writing system as close and strictly linked but independent phenomena, my aim is to study by NSM approach Naxi and Dongba for:
- identification of Naxi metalanguage semantic core
- identification of Dongba meta-pictographs semantic core
- confronts and among Naxi and Dongba cores for patterns and relationship identification and analysis
References
CL.A.U.D.I.A.s. is implemented as an instrument for development of Dongba pictographic writing system resources, thus one of the most important score to satisfy seemed to me being a system of records and quotations of existing references for each pictograph.
Thus CL.A.U.D.I.A. Disposes for each pictograph main Dongba/Naxi dictionaries quotation to make enjoyable all source material from which CL.A.U.D.I.A. plates took origins, also giving to users source's orthography from where CL.A.U.D.I.A.'s PINYIN and IPA were reconstructed.
Works considered at today in CLAUDIAs implementation are:
- 方国瑜; 和志武 - Fang Guoyu; He Zhiwu, 1995 纳西象形文字谱 - Naxi xiang xing wen zi pu" 云南人民出版社 : 云南省新華書店发行, Kunming Shi : Yunnan ren min chu ban she: Yunnan sheng xin hua shu dian fa xing, - isbn 7222017518. In CLAUDIA abbreviated in FG.
- 和品正 - Hè pǐn zhèng, 2004 " 東巴常用字典(漢英対照) - Naxi Dongba Pictographic Dictionary" 雲南美術 - isbn 7806951687. In CLAUDIA abbreviated to HPZ.
- Dragan Janekovic, 2005 "Na-si: srpski recnik" - Beograd: Narodna biblioteka Srbije. Here DJ.
- Joseph Francis Charles Rock, 1963: "A 1Na-2Khi-English encyclopedic dictionary", Serie Orientale Roma, XXVIII, 1. Abbreviated in JR.I.
- 李霖灿; Li Líncàn, 2001 "纳西族象形标音文字字典 - naxizu xiangxing biao yin wenzi zidian", 云南民族出版社 Yúnnán Mínzú Chubanshè - isbn 7-5367-2126-9. In CALUDIA as LLC.
Others foundamental works for reconstruction of PINYIN and IPA are:
- Michailovsky, Boyd; Michaud, Alexis, 2006 " Syllabic inventory of a Western Naxi dialect, and correspondence with Joseph F. Rock's transcriptions " Cahiers de linguistique - Asie Orientale 35: 3-21
- McKhann Charles, 1992 "e;Fleshing out the Bones: Kinship and Cosmology in Naqxi Religion"
- Jim Goodman, Jim Goodma1997 "e;Children of the Jade Dragon: The Naxi of Lijiang and Their Mountain Neighbours the Yi"
- F. ALBANO LEONI-P. MATURI,\995 "e;Manuale di fonetica", Roma.
- IPA - the International Phonetic Association: http://www.langsci.ucl.ac.uk/ipa/
- The International Phonetic Alphabet in Unicode: http://www.phon.ucl.ac.uk/home/wells/ipa-unicode.htm
Attestation
CLAUDIAs is isnpired and derived from the most important works of history of Egyptology as:
- Alan Gardiner, 1927 "Egyptian Grammar: Being an Introduction to the Study of Hieroglyphs"
- Adolf Erman and Hermann Grapow, "Wörterbuch der ägyptischen Sprache (Dictionary of the Egyptian language) "
As introduced upper, index plates structure realted to dictionary is derived form Gradiner's landmark work as appendix of "Egytpian Grammar", but complete dictionary and detailed analysys of each pictograph derived form Erman & Grapow's Wörterbuch, a complete of attestation and variants (also chronologically specified) dictionary of Egyptian hieroglyphs, as emeplified below.

Erman & Grapow's Wörterbuch 1st dictionary page. At the top page the common form of hieroglyph, in the middle column meanings and historical setting of each meaning; on left and right columns rispectively principal attestation and variants.
Humbly following Wörterbuch sample CLAUDIAs is implemented to record attestations relative to each pictograh: attestation research works should consist in a open field activities to be made by consulting, translating and confrontig the whole material available at today, both phisically and virtually by online corpora dedicated to Naxi's manuscript tradition.
The most important corpora dedicated to Naxi manuscripts at today are:
- Selections from the Naxi Manuscript Collection: http://memory.loc.gov/intldl/naxihtml/naxihome.html of the Library of Congress
- Harvard University Library OASIS project (Online Archival Search Information System): http://oasis.lib.harvard.edu/oasis/deliver/deepLink?_collection=oasis&uniqueId=hyl00002
CL.A.U.D.I.A. is implemented as a resources directly related and interactive with online corpora of Dongba pictographs manuscript tradition, which from a L.C. point of view consists it PICTOGRAPHS ECOLOGICAL SETTING; for a better and deeper discussion of Dongba manuscripts corpus, please, visit Do.M.En.I. project.
Draft digital encoding of Dongba manuscripts
Attestation, when available, are represented in CLAUDIA as:
- quotation of manuscript identification where pictograph are attested, for instance ms. 6080: 4 VIII, which is Rock's collection manuscript number 6080, page 4 rubric 8. Same kind of quotations for others paper source available.
- if manuscript is somehow available by online resources (Library of Congress and/or OASIS) CLAUDIA's references field show miniature reproduction of manuscript page and, if implemented, linked to its facsimile direct source URL and/or to dedicated encoding work.
Digital facsimiles
According to TEI recommendations, "a digital facsimile may, in the simplest case, just consist of a collection of images, with some metadata to identify them and the source materials portrayed. It may sometimes contain a variety of images of the same source pages, for example of different resolutions, or of different kinds. Such a collection may form part of any kind of document, for example a commentary of a codicological or paeleographic nature, where there is a need to align explanatory text with image data. And it may also be complemented by a transcribed or encoded version of the original source, which may be linked to the page images."
OASIS and Library of Congress Dongba manuscripts corpora are both databases of digital facsimiles of manuscript, thus CLAUDIA presents for each pictograph which is attested in OASIS and/or Library of Congress a miniature of manuscript page linked to original source.
For instance, pictograph
Eb.31 attestations list quotes an aivailable online manuscript digital
facsimile retrieved from Library of Congress Naxi's manuscript corpus:
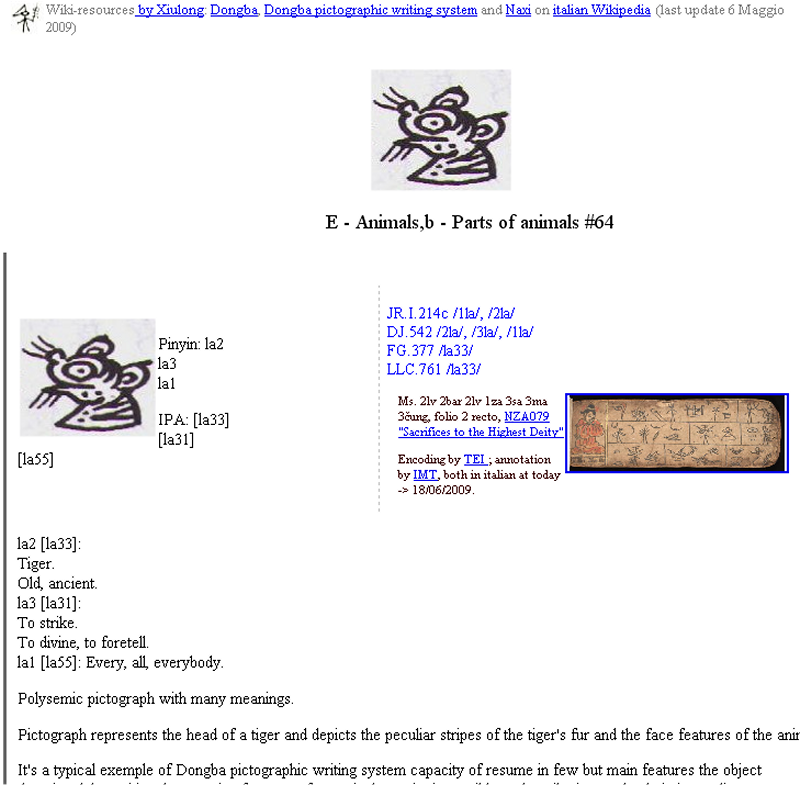
Attestations list presents a resized image of digital facsimile directly hiper-linked to the source retrieved and dislpaing local identification code record: by clicking CL.A.U.D.I.A. directly takes user to external source.
Digital Encoding of manuscripts by TEI and closer markup of manuscript pages by IMT
Previous attestation retrieved and implemented in CL.A.U.D.I.A. takes user to relative digital fascimile of manuscript page: in previous sample from Library of Congress database.Such kind of source and attestation, although very important for Dongba tradition and pictographic writing system scholars, from a L.C. point of view of digital text encoding is just comparable to a "0 level" of text encoding. (Lenci et al., 2005: 57)
CL.A.U.D.I.A. is implemented as an open project bounding to deeper
then "0 level" of encoding initiatives about dongba manuscripts,
thus beside OASIS and Library of Congress facsimiles resources CL.A.U.D.I.A.
also links to a
Draft works of project encoding Dongba manuscripts on Xiulong.it/Dongba presents 3 levels of text encoding:
- digital facsimile of one manuscript,
- encoding rubric by rubric of each page of Dongba manuscript. This
level of encoding provides to explicit:
- latinization (pinyin) of pictographs in rubric
- transcription of EFFECTIVE reading, often different from objective latinization of pictograph
- translation
- comments to the rubric
- closer encoding of each pictograph by direct mark-up on digital facsimile image by IMT - Image Markup Tool

For detailed introduction to Xiulong's Encoding Drafts of Dongba manuscripts
please, visit
dedicated pages (in Italian language), also with more detailed information
about The UVic Image Markup Tool Project (hence IMT) deveolped by Martin
Holmes, used on Xiulong.it/Dongba for 3
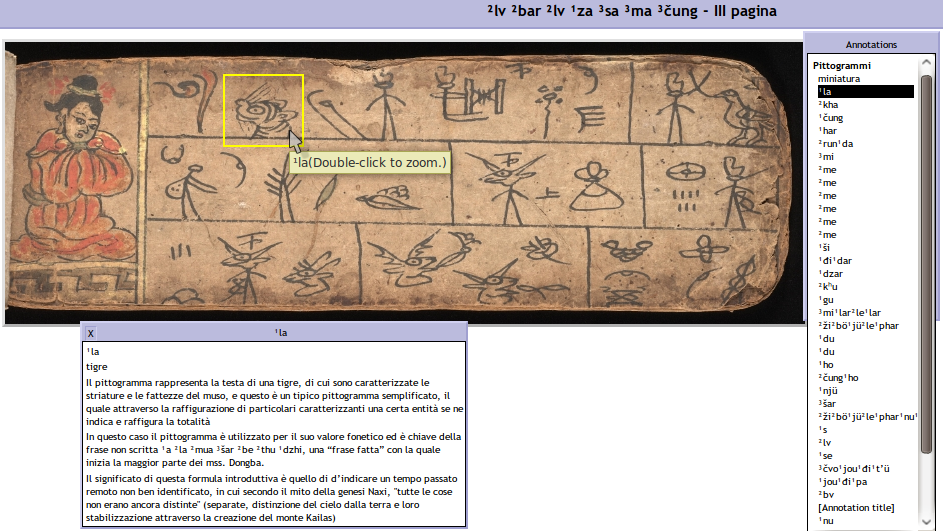
CLAUDIA is thus a hiper-bridge among digital humanities reources focused about Dongba manuscript study available at today.
My aim is, while collecting and classify pictographs into CL.A.U.D.I.A.'s plates, to develop a whide research project focused about creation of a international digital corpus of Dongba manuscripts - Do.M.En.I.; please visit dedicated pages to deeper information about.
